PostgreSQLにおいて、データに重複があり内1レコードを残して他の重複レコードを削除するにはどのようにすればよいのか、重複データの確認方法と削除の方法をまとめました。
重複データの確認
削除の前に、まずは重複データの確認方法からです。
今回のブログで使用するテーブルの構造やデータは以下になります。
●テーブル構造 テーブル:test_table 項目1:a(VARCHAR(1)) 項目2:b(VARCHAR(1)) 項目3:c(VARCHAR(1)) 論理的な一意キーは、a+b ●データ a | b | c ---+---+--- 1 | 1 | 1 2 | 1 | 1 2 | 1 | 2 2 | 2 | 1 2 | 2 | 2 2 | 2 | 3 3 | 3 | 9 3 | 3 | 9 3 | 3 | 9
一意になるはずのキーで集約し、件数が1件より大きいデータを抽出します。
HAVING句を使用することで集約後の値に対して条件を指定できます。
SELECT a
,b
,COUNT(*) cnt
FROM test_table
GROUP BY a
,b
HAVING COUNT(*) > 1
;
a | b | cnt
---+---+-----
2 | 1 | 2
2 | 2 | 3
3 | 3 | 3
重複データを削除
対象テーブル内の重複データを削除する場合、どのデータを残してもよい場合(すべての項目が同じ値の場合含む)と、特定の項目で優先順位をつける場合で方法が異なります。
どちらも、全体のデータ件数が多い場合や重複するデータ数が多い場合は、処理時間がかかることが想定されるます。事前に十分な検証を行いましょう。
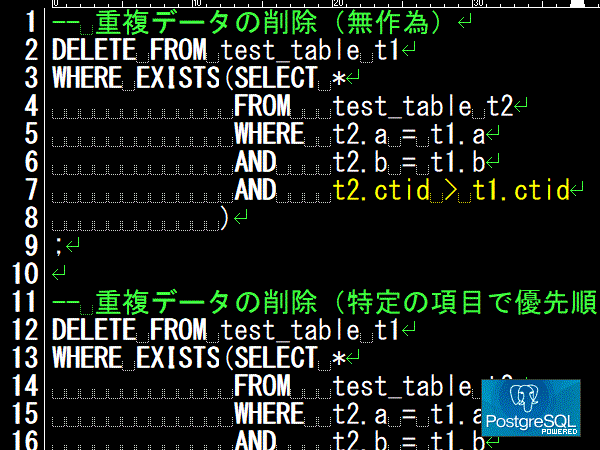
どのデータを残してもよい場合(すべての項目が同じ値の場合含む)は、PostgreSQLによって暗黙的に定義されているctidシステム列を利用します。ctidは、テーブル内において行の物理的位置を表していて、一意であることを利用します。
DELETE FROM test_table t1
WHERE EXISTS(SELECT *
FROM test_table t2
WHERE t2.a = t1.a
AND t2.b = t1.b
AND t2.ctid > t1.ctid
)
;
残したいデータに優先順位をつける場合(一意キー以外の項目で差異が全くない場合は、1レコードだけ残るように削除する)は、複数回DELETE文を発行します。
以下は、項目cが大きい値を優先して残す場合です。
-- 項目cが最大値以外のデータを削除する(最大値が複数ある場合はそれが残る)
DELETE FROM test_table t1
WHERE EXISTS(SELECT *
FROM test_table t2
WHERE t2.a = t1.a
AND t2.b = t1.b
AND t2.c > t1.c
)
;
-- ctidシステム列を利用して、重複行を削除
DELETE FROM test_table t1
WHERE EXISTS(SELECT *
FROM test_table t2
WHERE t2.a = t1.a
AND t2.b = t1.b
AND t2.ctid > t1.ctid
)
;
少し複雑になりますが、1回のSQLでDELETE文で削除することも可能です。
DELETE FROM test_table t1
WHERE EXISTS(SELECT *
FROM test_table t2
WHERE t2.a = t1.a
AND t2.b = t1.b
AND ( t2.c > t1.c
OR ( t2.c = t1.c
AND t2.ctid > t1.ctid
)
)
)
;
最後に
重複データの削除方法、実際に発生するとどうやって削除しようか戸惑うポイントかと思います。
本番運用時に発生し、解決まで時間の猶予なし、ということもあります。
いざ発生しても焦らないように解消方法を頭に入れておきましょう。
また、DBによって方法も異なるのも注意が必要です。(例えば、ORACLEではROWID擬似列を利用する)